Northcutt NeurIPS’21 Pervasive Label Errors in Test Sets Destabilize Machine Learning Benchmarks¶
著者
Curtis G. Northcutt (MIT)
Anish Athalye (MIT)
Jonas Mueller (AWS)
Abstract¶
最も一般的に利用されているコンピュータビジョン、自然言語、オーディオの10種類のデータセットのテストセットにおけるラベルエラーを特定する
その後、これらのラベルエラーがベンチマーク結果に影響を与える可能性について研究している
例えば、ImageNetの検証セットでは、ラベルエラーが少なくとも6%あった
10個のデータセット全体で少なくとも3.3%のエラーがあった
ラベルエラーの候補はCLで特定し、その後クラウドソーシングを通じて人間によって検証される
CLよってフラグが立てられた候補の51%は実際にラベルエラーだった
(意外なことに、)誤ってラベル付けされたデータの割合が高い実世界のデータセットでは、パラメータの少ないモデルの方がパラメータの多いモデルよりも実質的に有用である可能性があることがわかった (いいすぎなのでは)
1 Introduction¶
データセットを構築するために使用されるプロセスは、ある程度の自動ラベリングやクラウドソーシングを含み、本質的にエラーが発生しやすい技術である
先行研究は、訓練セットのノイズに焦点を合わせており、テストセットにおけるラベルエラーはあまり研究されていない
テストセットにおけるラベル付きデータは訓練セットと同じ分布から抽出されている限り「正しい」とみなされることが、それは誤り

貢献は以下の通り
10種類の標準的なベンチマークのテストセットにおけるラベルエラーの発見
各テストセットのクリーニングと修正のためのOSSのリリース
テストセットのラベルエラーがベンチマークに与える影響の分析
誤ってラベル付けされたテストデータでは、高容量モデルが元の(ノイジーな)ラベルに対する精度では良い性能を発揮するが、ノイジーなものを修正したラベルに対する精度では悪い性能であるという結果を示した
テストラベルの誤差がわずかに増加するだけで、誤ったモデル選択をしてしまうということ
3. Identifying label errors in benchmark datasets¶
CLを人間の検証を必要とする例の数を有意に減らすためのフィルターとして使うよ的なことしか言っていない
4. Validating label errors with Mechanical Turk¶
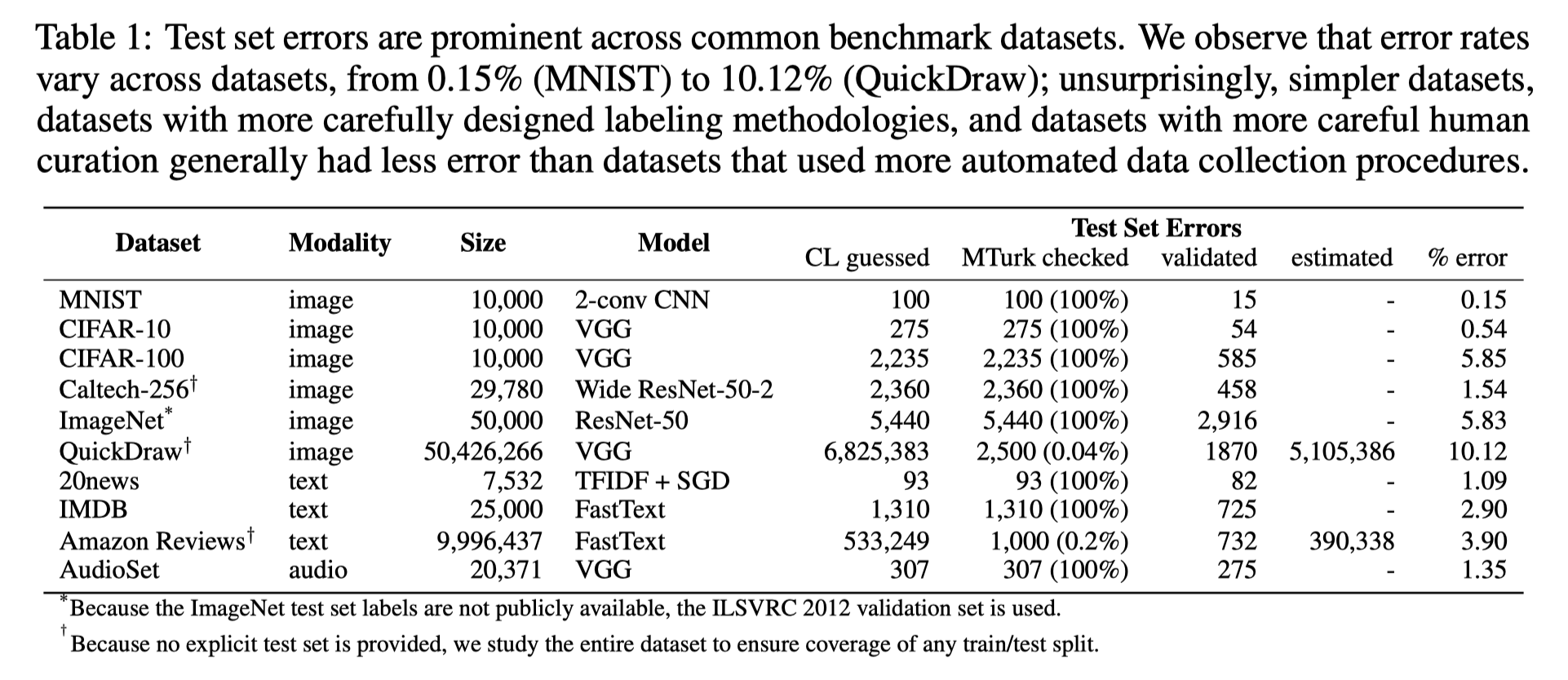
表1: 検証するデータセットのサイズやCLでフラグ付られた数、そのうちMTurkにかけた数、そのうち訂正された数、ラベルエラーの推定数、ラベルエラーの%
CL guessedが多かったQuickDrawとAmazon Rewviewsについてはランダムサンプリングしてチェックした
作業者に (1)与えられたラベル、(2)CLが予測したラベル、(3)両方のラベル、(4)どちらのラベルでもないを選択してもらった
一つのサンプルを対して5人のワーカーに提示して、3人より多くのワーカーが与えられたラベルが正しいとした場合はエラーでないとして、同意するのが3人以下だった場合はその例をエラーとみなした
さらにラベルエラーを分類し、(1) CLが予測したラベルが正しい、(2) マルチラベル、(3)どちらでもない、(4)非合意に分類した
表2に結果を、図1に検証したラベルエラーの例を示す。
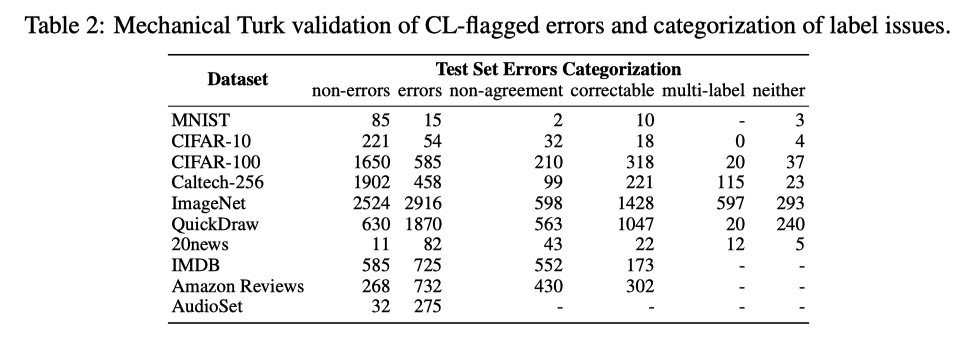

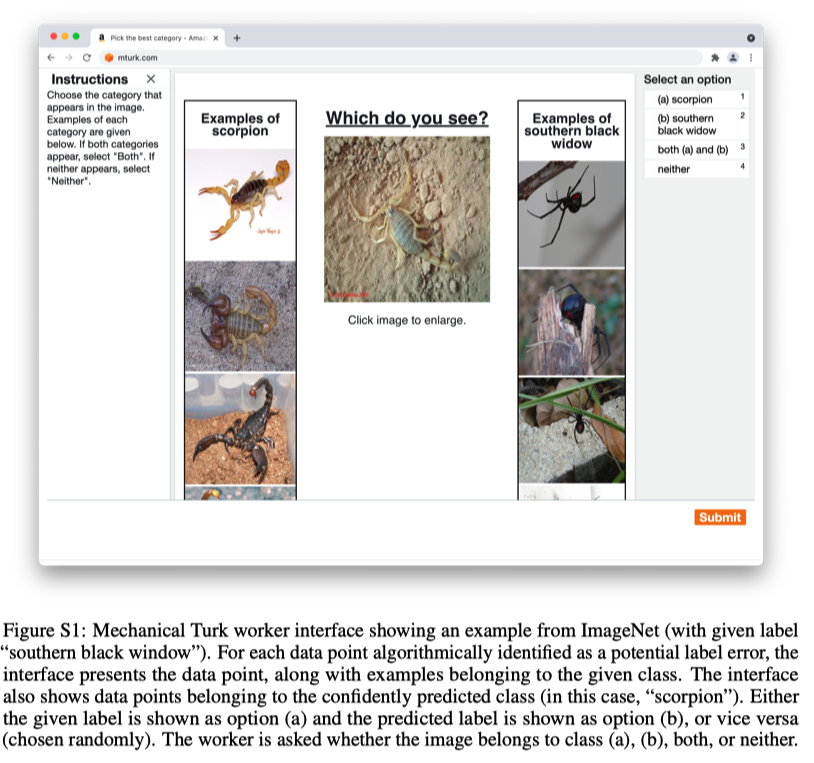
Figure S1 は実際のMTrukのワーカーの使うインターフェースのスクショ
5. Implications of label errors in test data¶
明確な議論をするために、いくつか記号を導入する
\(\tilde{A}\) original accuracy: 与えられた(オリジナルな)データセットに対してモデルが予測するラベルの精度
\(A^*\) corrected accuracy: 定された誤ったラベルを可能な限り修正し、不可能な場合は削除した修正データセットに対して計算されるモデルの精度
\(\mathcal{D}\) : full test dataset
\(\mathcal{B}\) benign set: CLがラベルエラーの可能性があると判断しなかったデータと、CLフラグが立ったが人間が元のラベルを維持すべきと合意したデータの集合 ( \(\mathcal{B} \subset \mathcal{D}\) )
\(\mathcal{U}\) unknown-label set: CL-flagged のデータで、人間が正しいラベルを1つも決められなかったサブセット。人間が複数のクラスまたはどのクラスも適切でないと合意したものが含まれる。( \(\mathcal{U} \subset \mathcal{D} \setminus \mathcal{B}\) )
\(\mathcal{P}\) pruned set: \(\mathcal{D}\) から \(\mathcal{U}\) を取り除いた残りのテストデータ ( \(\mathcal{P} \subset \mathcal{D} \setminus \mathcal{U}\) )
\(\mathcal{C}\) correctable set: CL-flagged なサンプルで人間がオリジナルのラベルとは異なるラベルだと合意したサンプルの集合 ( \(\mathcal{C} \subset \mathcal{D} \setminus \mathcal{B}\) )
\(N\) noise prevalence: unknown-label set を除いたうち、ラベルエラーだと判定された割合 ( \(N = \frac{\mathcal{C}}{\mathcal{P}}\) )
MLにおける大きな問題は、きれいなテストセットの精度を見るべきなのに、実際にはノイジーかもしれないテスト精度を見ているだけ。このミスマッチがもたらす潜在的な影響について考察する
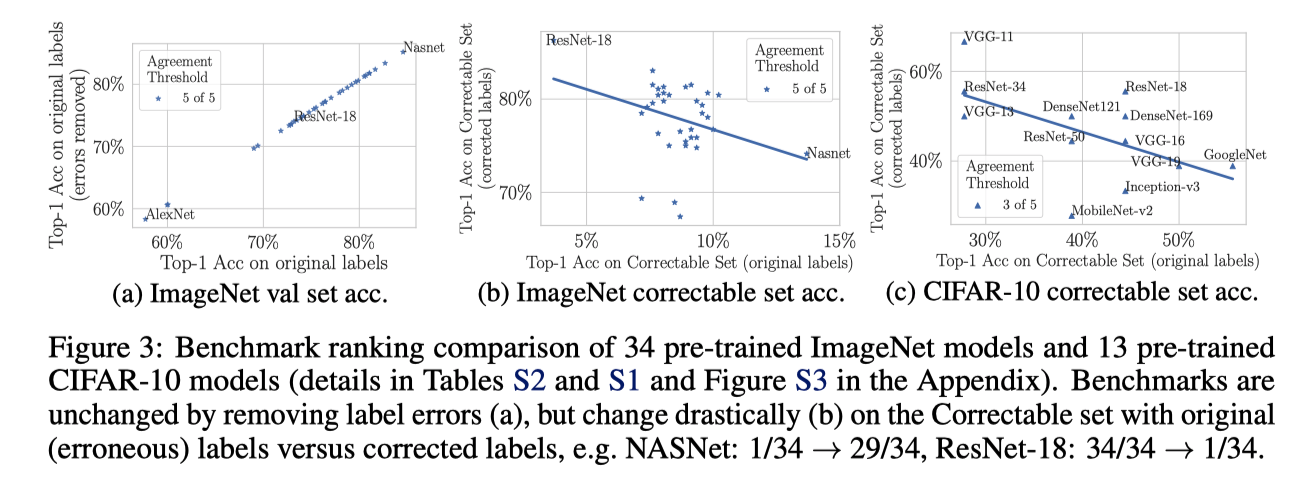
図3は、PyTorchとKerasのリポジトリにある34の事前学習済みモデルについて、ImageNet検証セットでの性能を比較している
図3(a) は、横軸がオリジナルのテストセットの精度、縦軸がオリジナルからラベルエラーを除いたセットの精度
順位変化はなくて、とても相関している
しかし,correctable set \(\mathcal{C}\) におけるモデルの性能を詳細に調べると,驚くべき結果が得られた
図3(b) は 横軸がImageNetにおける:math:mathcal{C} のオリジナルラベルにおける精度、縦軸が修正したラベルにおける精度 - 元の(誤った)ラベルで最高の性能を示したモデルは,修正後のラベルでは最悪の性能となる - 例えば、ResNet-18は、元のテスト精度がはるかに悪いにもかかわらず、NASNet [50]を有意に上回る - ランキングの変化は劇的で、NASNet-large は 1/34 -> 29/34、Xceptionは2/34 -> 24/34、ResNet-18は34/34 -> 1/34、ResNet-50は20/24 -> 2/24
図3(c)はCIFAR-10版
この現象は、2つの重要な洞察を示していると考えられる
低容量のモデルは予期せぬ正則化の恩恵をもたらし、ノイズの多いラベルの非対称分布の学習に強い
より新しい(大容量な)モデルは、オリジナルのテスト精度に基づいてアーキテクチャ/ハイパーパラメータが決定されている。(?)
2 は古典的な意味でのover-fittingではなく、特定のベンチマーク(およびオリジナルのラベル注釈者の癖)に対するover-fittingであり、誤ったラベルに対する精度向上は、展開されたMLシステムにおいて優れた性能にならない可能性があることを示しています。(?)
Note
\(\mathcal{C}\) のサイズはImageNetでは5.83%, CIFAR10では0.54%と大きくはない
すべれのラベルエラーを訂正できてるわけではないが、\(\mathcal{P}\) に対して修正したラベルの精度で精度をみてランキングが変動していなければ問題ないのでは?
5.2 Benchmark instability¶
テストセット中のラベルエラーの割合による変化するかを調べるために、正しくラベル付けされた例を一度に一つずつランダムに漸進的に削除し、元の誤ラベル付きテストデータセット(修正ラベル付き)のみが残るようにした。
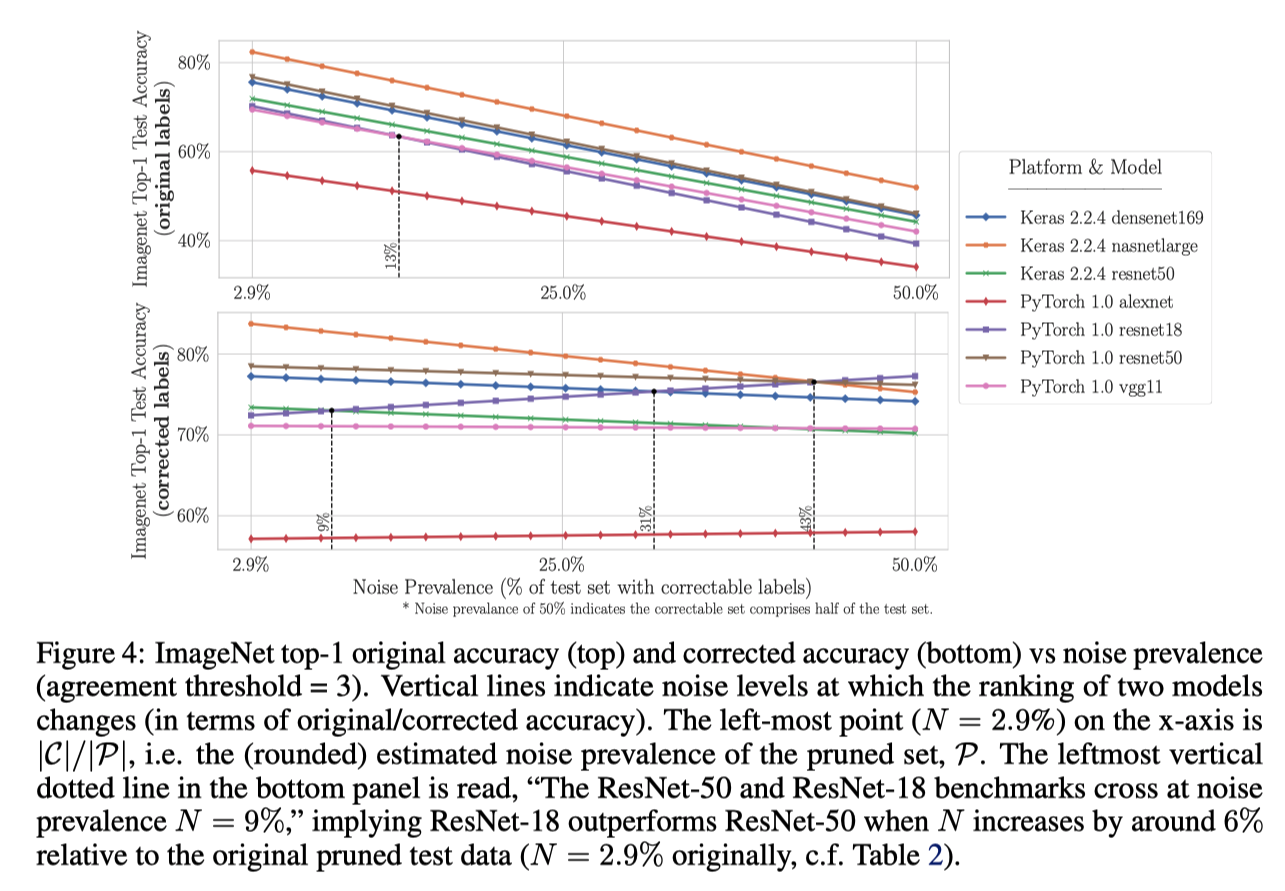
横軸: N (Noise Prevalencce)
縦軸: オリジナルラベルの精度(上)、訂正したラベルの精度(下)
N=43%くらいで、NASNetとResNetが逆転する
6. Expert review of CL-flagged and non-CL-flagged label errors in ImageNet¶
ここまで、CL-flagged のサンプルだけ調査してきた
この章では以下の疑問に対して取り組んでいく
CL-flagged のサンプルはランダムな部分集合よりも本当に誤りが多いのか?
CL-flagged でないサンプルではどれだけのラベルエラーが見逃されるのか?
専門家と比較して、MTurkはどの程度信頼できるのか?
専門家によるレビューは2段階で行われた
専門家が1,000のImageNetクラスから CL-flaggedと非CL-flaggedのそれぞれランダムにサンプリングして評価した
専門家はMTurkワーカーと同様のインターフェースで同じ選択肢の中から一つを選択する
専門家は知らないクラスがあれば、関連画像や分類情報をオンラインで調べ、1つのラベルにつき、MTurk作業者の平均13倍以上の時間を費やした
各画像は少なくとも2人の専門家によってレビューされ、専門家は77%の画像は合意に至った
不一致があった残りの23%について、すべての専門家が共同で再検討を行い合意を得る

CL-flaggedなサンプルはそうでないものに比べ、ラベル問題が有意に高い割合(2.6倍)で存在する
人間がレビューのための予算が限られている場合、大規模なデータセットのラベルを検証する際に、CLを使って優先するサンプルを決めるのをおすすめする
CL(expert) と CL(MTurk)を比較すると、exprtがどちらのラベルも適切ではないと判断したケースでもMTurkのワーカーはラベルの修正を優先していることがわかる
専門家がタスクで提示された2つのラベルの選択肢より良い選択肢を知っていることに起因すると考えられる
しかし、MTurkの結果は全体的に専門家によるレビューの結果と一致している
さらに、89%のCLによってフラグがつけられていないもののうち、約16%が誤ラベルであることを示しているた
5章の分析はImageNetのラベルエラーの約14%を見逃していると推定される
ImageNet検証セットには(表1の6%から)20%近いラベルエラーが含まれていると推定できる。