Grover ICLR’19 Stochastic Optimization of Sorting Networks via Continuous Relaxations¶
https://openreview.net/forum?id=H1eSS3CcKX
著者
Aditya Grover (Computer Science Department Stanford University)
Eric Wang (Computer Science Department Stanford University)
Aaron Zweig (Computer Science Department Stanford University)
Stefano Ermon (Computer Science Department Stanford University)
概要¶
sortをargmaxを用いて記述 → argmaxをsoftmaxで代替して微分可能にする
順列の確率がPlackett-Luce分布に従うとした設定のversionも提案
前置き¶
Permutation matrixの定義
まずPermutation matrixを導入します。
\(\mathbf{z} = [z_1, \ldots, z_n]^\top\) を長さnのユニークインデックス \(\{1, 2, \ldots, n\}\) のリストとする (zの取りうる集合を \(\mathcal{Z}_n\) とする)
そして \(\mathbf{z}\) のpermutation matrix \(P_{\mathbf{z}} \in \{0, 1\}^{n \times n}\) を以下のように定義する (\({P_{\mathbf{z}} [i, j]}\) は \((i, j)成分\) )
具体例
\(\mathbf{z} = [1, 3, 4, 2]^\top\) とすると \(\mathbf{z}\) のPermutation Maxtrixは以下になる。
sort関数の定義
そして、\(\mathbf{s} = [s_1, \ldots, s_n]^\top\) を長さ \(n\) の実数のベクトル、 \([i]\) を \(\mathbf{s}\) の中で \(i\) 番目に大きい値のindexとして、 sort関数 \(\mathbb{R}^n \to \mathcal{Z}_n\) を次のように定義します。
そうすると ベクトル \(\mathbf{s}\) を(降順に)ソートしたベクトルは \(P_{\text{sort}(\mathbf{s})} \mathbf{s}\) と書けるようになる。
具体例
\(\mathbf{s} = [9, 1, 5, 3]^\top\) とすると
1番大きい9のindexは1, 2番目に大きい5のindexは3、・・・なので \(\text{sort}(\mathbf{s}) = [1, 3, 4, 2]^\top\) になる
そして、\(\text{sort}(\mathbf{s})\) のPermutation matrixは定義より以下となる
そして \(P_{\text{sort}(\mathbf{s})} \mathbf{s} = [9, 5, 3, 1]\) となるので、ちゃんとソートされている。
Corollary 3 (sortを数学的に記述する)
\(\mathbf{s}\) の要素間の差の行列を \(A_{\mathbf{s}}\) とする (つまり \(A_{\mathbf{s}}[i,j] := |s_i - s_j |\))
すると、\(\text{sort}(\mathbf{s})\) のPermutation matrix \(P_{\text{sort}(\mathbf{s})}\) は以下になる
(\(\mathbb{1}\) は要素がすべて1のcolumn vector)
具体例
\(\mathbf{s} = [9, 1, 5, 3]^\top\) とすると \(A_{\mathbf{s}}\) は以下になる
\(i = 1\) のとき、以下なので \(\arg \max [(n+1-2i) \mathbf{s} - A_{\mathbf{s}} \mathbb{1} ] = \arg \max[9, -11, 5, -1] = 1\)
\(i = 2\) のとき、以下なので \(\arg \max [(n+1-2i) \mathbf{s} - A_{\mathbf{s}} \mathbb{1} ] =\arg \max [-9, -13, -5, -9] = 3\)
\(i = 3\) のとき、以下なので \(\arg \max [(n+1-2i) \mathbf{s} - A_{\mathbf{s}} \mathbb{1} ] = \arg \max [-27, -15, -15, -13] = 4\)
\(i = 4\) のとき、以下なので \(\arg \max [(n+1-2i) \mathbf{s} - A_{\mathbf{s}} \mathbb{1} ] = \arg \max [-45, -17, -25, -19] = 2\)
\(\text{sort}(\mathbf{s}) = [1, 3, 4, 2]^\top\) なのであっている。
提案法: NeuralSort¶
モチベーション
次のようなsortを含む目的関数をgradient-based methodで最適化することが目標 (\(\theta\) がモデルパラメータで \(\mathbf{s}\) が \(\theta\) に依存)
提案法
argmaxは微分できないので、softmaxで置換して、sortのPermutation matrixを以下のようにrelaxationする。 (\(\tau\) は温度パラメータ)
tensorflowで実装すると次のような感じ(batch版)
import tensorflow as tf
def neural_sort(s, tau=0.1):
m = s.shape[0]
n = s.shape[1]
es = tf.repeat(tf.expand_dims(s, axis=1), n, axis=1)
A = tf.abs(tf.transpose(es, perm=[0,2,1]) - es)
i = tf.range(1, n+1, dtype=tf.float32)
A1 = tf.repeat(tf.expand_dims(tf.reduce_sum(A, axis=1), axis=1), n, axis=1)
pi = tf.multiply(n+1-2*i[:, None], es) - A1
pm = tf.nn.softmax(pi/tau)
sort_s = tf.linalg.matvec(pm, s)
b_hat = tf.expand_dims(tf.repeat(i[None, :], m, axis=0), axis=2)
rank_s = tf.linalg.matmul(pm, b_hat)[...,0]
return sort_s, rank_s
s = tf.constant([[9,1,5,3,], [-6.5, 0.4, 1.5, 3.8,]])
ss, sr = neural_sort(s)
print("s =\n", s.numpy())
print("sort(s) =\n", ss.numpy())
print("rank(s) =\n", sr.numpy())
s =
[[ 9. 1. 5. 3. ]
[-6.5 0.4 1.5 3.8]]
sort(s) =
[[ 9. 5. 3. 1. ]
[ 3.8 1.4999816 0.4000184 -6.5 ]]
rank(s) =
[[1. 3. 4. 2. ]
[4. 2.9999833 2.0000167 1. ]]
Theorem 4
Limiting behavior: \(\mathbf{s}\) の各要素が \(\mathbb{R}\) のルベーグ測度に対して絶対連続な分布から独立に引かれていると仮定すると、以下が成り立つ
Unimodality: \(\forall \tau > 0\) において \(\hat{P}_{\text{sort}(\mathbf{s})}\) は unimodal row stochastic matrixである。さらに、 \(\hat{P}_{\text{sort}(\mathbf{s})}\) の各行にargmaxを取ったベクトルは \(\text{sort}(\mathbf{s})\) に一致する。
Limiting behaviorについて
\(\text{hardmax}(\mathbf{s})\) を \(i := \arg \max(\mathbf{s})\) としてindex iだけが1で他のindexが0のベクトルを返す関数だとする
\({P}_{\text{sort}(\mathbf{s})} [i, :] = \text{hardmax}((n+1-2i) \mathbf{s} - A_{\mathbf{s}} \mathbb{1})\) とかける
で \(\text{hardmax}(\mathbf{s}) = \arg \max_{\mathbf{x} \in \Delta^n } \langle \mathbf{x},\mathbf{s} \rangle\) とも書ける
一方softmaxは次のように書ける (ラグランジュの未定乗数法を使った softmaxの変形の証明)
なので \(\lim_{\tau \rightarrow 0^+} \text{softmax}(\mathbf{s}/\tau) = \arg \max_{\mathbf{x} \in \Delta^n } \langle \mathbf{x},\mathbf{s} \rangle = \text{hardmax}(\mathbf{s})\) なので
\(\lim_{\tau \rightarrow 0^+} \hat{P}_{\text{sort}(\mathbf{s})} [i, :] (\tau) = {P}_{\text{sort}(\mathbf{s})} [i, :] ~~~ \forall i \in \{1,2,\ldots, n\}\)
Unimodalityについて
まず定義します。
Definition 1 (Unimodal Row Stochastic Matrices): 以下の3つを満たす行列のこと
Non-negativity: \(U[i,j] \geq 0 ~~~ \forall i, j \in \{1,2,\ldots, n\}.\)
Row Affinity: \(\sum_{j=1}^n U[i,j] = 1 ~~~ \forall i, j \in \{1,2,\ldots, n\}.\)
Argmax Permutation: \(u_i = \arg \max_j U[i, j]\) とすると \(\mathbf{u} \in \mathcal{Z}_n\) であること (つまり \(\mathbf{u}\) がvalid permutationであること)
証明
Non-negativity, Row Affinity はsoftmaxの定義より成り立つ。
Argmax Permutationは以下がなりたち、 \(\mathbf{u} = \text{sort}(\mathbf{s})\) なので成り立つ。
Unimodalityがあるとなにが嬉しいのか?
特に論文中に説明はなかったが、\(P_{\text{sort}(\mathbf{s})}\) が持っている性質なので \(\hat{P}_{\text{sort}(\mathbf{s})}\) も同じ性質を持っているからいいよねって感じだと思いました
(疑問)
実践的にはsoftmaxよりsoftargmaxのほうがいいんじゃないかと思ったが、どうなのだろうか
DCGに適用した場合、ApproxNDCG (Approx NDCGについて詳しく) と結果的にはあんまりかわらないんじゃないかという気がしてきた
Stochastic Optimization over Permutations¶
今までは
今度は以下を考える (\(q(\cdot)\) は \(\mathcal{Z}_n\) の要素上の分布)
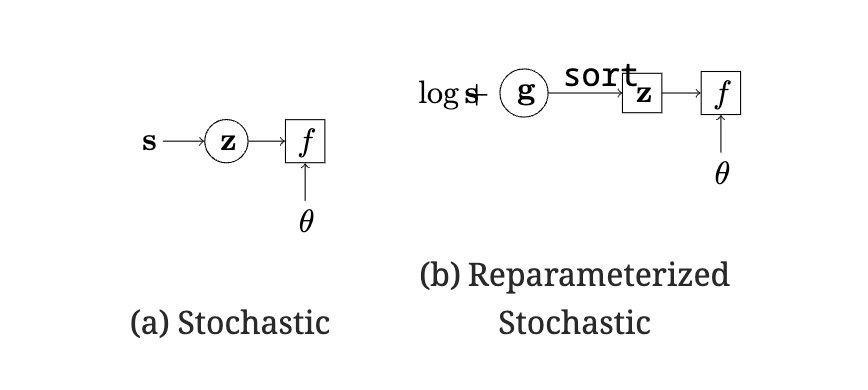
MCMCで \(\theta\) に関する勾配の不偏推定量は得られるが、sampling distributionが \(\mathbf{s}\) に依存するため、\(\mathbf{s}\) に関する勾配の推定量は直接求められない。
REINFORCE gradient estimator (Glynn, 1990; Williams, 1992; Fu, 2006) は \(\nabla_s q(\mathbf{z}|\mathbf{s}) = q(\mathbf{z}|\mathbf{s}) \nabla_s \log q(\mathbf{z}|\mathbf{s})\) を使って、 MC gradient estimationは
だが、REINFORCE gradient estimator は High Varianceに苦しんでいる (Schulman et al., 2015; Glasserman, 2013).
reparameterization trickを使うと、 \(\mathbf{g}\) をgumbel noiseとして 式 (4) は以下になる
となり、argmaxをsoftmaxで置換して緩和したsortにして、微分したものは
これは、期待値がsに依存しない分布に関するものであるため、モンテカルロ法で効率的に推定できる。
(実験をみると Stochasticにしても性能が上がるわけではない)
Proof of Corollary 3¶
まず Lemma 2 [Lemma 1 in Ogryczak & Tamir (2003)]
(書きかけ)
softmaxの変形の証明¶
ラグランジュの未定乗数法を使うと、ラグランジュ関数は
(第三項は足して1の制約から、第四項はすべての要素が非負の制約から)
スレーター制約を満たすのでKKT条件が最適性の必要十分条件になって、KKT条件は以下。
1つ目の条件から
となるので \(x_i > 0\) になり、また \(\lambda_i x_i = 0\) なので \(\lambda_i = 0\) になる。
2つ目の条件と式 (6) から
また、式 (6) から
よって、以下になる。