Cuturi NeurIPS’19 Differentiable Ranks and Sorting using Optimal Transport¶
https://arxiv.org/abs/1905.11885
著者
Marco Cuturi (Google Research, Brain Team)
Olivier Teboul (Google Research, Brain Team)
Jean-Philippe Vert (Google Research, Brain Team)
概要¶
sortは最適輸送問題の一種
(正則化をした)最適輸送の問題はsinkhorn algorithmで解ける
sinkhorn algorithmは行列演算で微分可能な手続きなので、sortも微分可能になりend-to-endで学習できる
前置き¶
最適輸送については以下あたりを読むと良さそう
最適輸送の理論とアルゴリズム (佐藤竜馬) (機械学習プロフェッショナルシリーズ) https://www.kspub.co.jp/book/detail/5305140.html
Optimal transport for applied mathematicians (Filippo Santambrogio)
Computational Optimal Transport (Gabriel Peyré and Marco Cuturi) https://arxiv.org/abs/1803.00567
最適輸送の定式化
最適化問題のイメージ
倉庫がn個、工場がm個あり、倉庫iには材料が \(a_i\) あって、工場jは材料を \(b_j\) 必要としている。
輸送コスト倉庫iから倉庫jへの輸送コストを \(C_{ij}\) とする。
そのとき、輸送コストが最小になる輸送を求めたい。
エントロピー正則化とシンクホーンアルゴリズム
最適輸送の理論とアルゴリズム (佐藤竜馬) の3章より
最適輸送を線形計画問題として定式化したがいくつか問題点がある
線形計画ソルバー計算量の問題(最悪入力サイズの3乗)
組み合わせてend-to-endでの学習はできない
\(a, b, C\) について滑らかでないので微分できない
そこでエントロピー正則化をつけた最適輸送問題を導入すると、その問題はiterativeな行列演算で解ける
ということは自動微分できて、end-to-endな学習に組み込める
エントロピー正則化つき最適輸送問題
シンクホーンアルゴリズム
\(A = \exp(-C/\epsilon), ~ u^{(0)} \leftarrow \mathbb{1}_n,~ v^{(0)} \leftarrow \frac{1}{{\lVert A \rVert}_1 } \mathbb{1}_m\)
for \(k=1,2,\ldots\) do
\(~~~~~ u^{(k)} \leftarrow \frac{a}{Ay^{(k-1)}}, ~ v^{(k)} \leftarrow \frac{b}{A^\top u^{(k)}}\)
シンクホーンアルゴリズムは (2) の最適解に収束する (最適輸送の理論とアルゴリズム (佐藤竜馬) の定理3.9)
\(\epsilon\) を十分小さくすれば、エントロピー正則化しない問題の最適解に近い解を得られることを示せる (最適輸送の理論とアルゴリズム (佐藤竜馬) の定理3.16)
end-to-endの学習に組み込むとき、イテレーション回数は \(1, 2, \ldots 10\) あたりにすることが多いらしい
Ranking and Sorting as an Optimal Transport Problem¶
Proposition 2(ソートは最適輸送の一種)
\(\mathbb{O}_n \subset \mathbb{R}^n\) を長さnのincreasing vectorの集合とする。 (例えば \([1.2, 2.4, 4.3] \in \mathbb{O}_3\) )
また、\(x\) を対象の長さnのベクトル、 \(y \in \mathbb{O}_n\) , \(h\) を非負な値を取る関数として、 \(C_{ij} = h(y_j - x_i)\) とする。
そして、\(n=m, a = b = \mathbb{1}_n / n\) とし、 \(h\) を狭義凸関数、 \(P_{\star}\) を (1) の最適解としたとき、以下が成り立つ。
補足: ここでのrank, sortは昇順。降順にするなら、\(y\) をdecreasing vectorにすればよい。
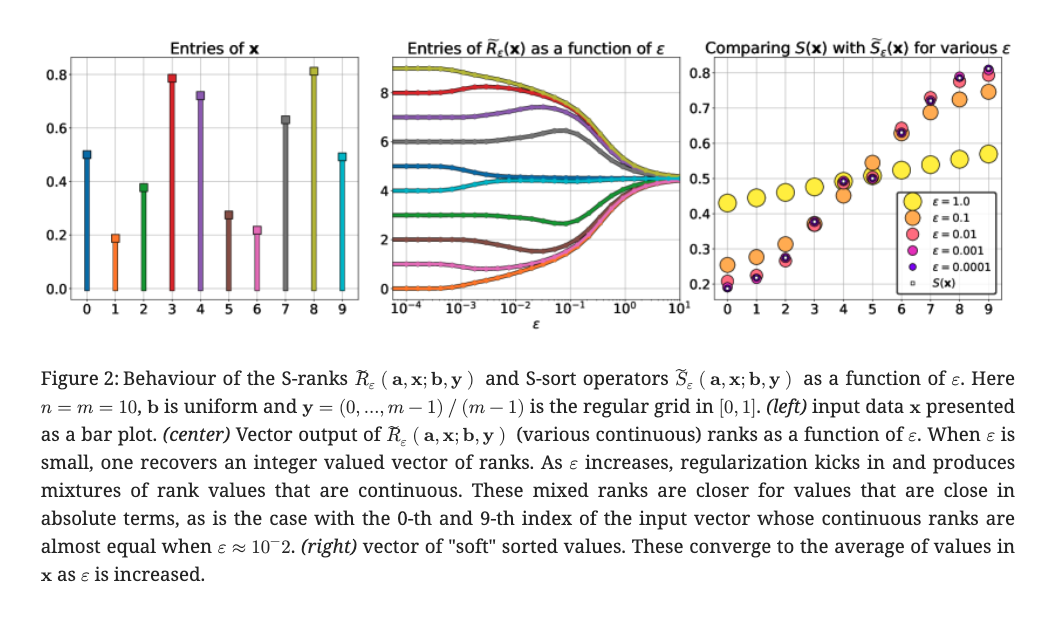
\(\epsilon\) を動かしたときに 緩和版rankと緩和版sortの出力がどうなるかを示したものがFig.2
左の図がsort対象のベクトルの要素の値
中央の図がrankがどう変化していくか(色は左の図の要素の色に対応)
右の図が緩和版sort関数の出力がどうなるか (色が:math:epsilon, 真のsortが◯)
tensorflowで実装すると以下のような感じ。
import itertools
import tensorflow as tf
def ot_sinkhorn(C, a, b, eps, itr):
K = tf.exp(-C / eps)
u = tf.ones_like(a)
for _ in range(itr):
v = b / tf.linalg.matvec(tf.transpose(K),u)
u = a / tf.linalg.matvec(K,v)
P = tf.reshape(u, (-1,1))*(K * tf.reshape(v, (1,-1)))
return u, v, P
def ot_sort(x, eps=0.1, itr=10):
l = x.shape[0]
y = (
tf.math.reduce_min(x)
+ (tf.range(l, dtype=tf.float32) * tf.math.reduce_max(x) / l)
)
# stop_gradient(y)
C = (
tf.repeat(y[None, :], l, axis=0)
- tf.transpose(tf.repeat(x[None, :], l, axis=0))
) ** 2
a = tf.ones_like(x) / l
b = tf.ones_like(y) / l
_, _, P = ot_sinkhorn(C, a, b, eps, itr)
b_hat = tf.cumsum(b, axis=0)
r = l**2 * tf.linalg.matvec(P, b_hat)
s = l * tf.linalg.matvec(tf.transpose(P), x)
return r, s
x = tf.constant([6.5, 0.4, 1.5, 3.8,])
print("x =", x.numpy())
for eps, itr in itertools.product([1.0, 0.5, 0.1, 0.02, 0.01], [10, 3, 1]):
r, s = ot_sort(x, eps, itr)
print(
"(eps, iter) =", (format(eps, '.2f'), itr),
", rank(x) =", r.numpy(),
", sort(x) =", s.numpy(),
)
x = [6.5 0.4 1.5 3.8]
(eps, iter) = ('1.00', 10) , rank(x) = [3.9968197 1.1420645 1.8819754 3.0264604] , sort(x) = [0.5554942 1.3809326 3.6119864 6.6515865]
(eps, iter) = ('1.00', 3) , rank(x) = [3.9989045 1.1250924 1.8521441 3.0912457] , sort(x) = [0.5925583 1.3958678 3.2627218 6.948852 ]
(eps, iter) = ('1.00', 1) , rank(x) = [3.9995468 1.0959185 1.8018403 3.2095122] , sort(x) = [0.67236686 1.3496025 2.7493656 7.428665 ]
(eps, iter) = ('0.50', 10) , rank(x) = [3.9999995 1.0188777 1.9609721 3.0395494] , sort(x) = [0.45122853 1.4556235 3.635775 6.6573734 ]
(eps, iter) = ('0.50', 3) , rank(x) = [3.9999998 1.0119616 1.9392414 3.0985882] , sort(x) = [0.48653013 1.4220234 3.4080822 6.883364 ]
(eps, iter) = ('0.50', 1) , rank(x) = [3.9999995 1.009408 1.923769 3.167692 ] , sort(x) = [0.51072514 1.3990191 3.1431415 7.1471143 ]
(eps, iter) = ('0.10', 10) , rank(x) = [3.9999998 1. 1.9999944 3.001144 ] , sort(x) = [0.40000835 1.4999917 3.7956526 6.504347 ]
(eps, iter) = ('0.10', 3) , rank(x) = [4. 1. 1.9999944 3.0011625] , sort(x) = [0.40000835 1.4999917 3.7955813 6.5044184 ]
(eps, iter) = ('0.10', 1) , rank(x) = [3.9999998 1. 1.9999944 3.0011683] , sort(x) = [0.40000835 1.4999917 3.7955613 6.5044384 ]
(eps, iter) = ('0.02', 10) , rank(x) = [4. 1. 2. 3.] , sort(x) = [0.4 1.5 3.8 6.5]
(eps, iter) = ('0.02', 3) , rank(x) = [4. 1. 2. 3.] , sort(x) = [0.4 1.5 3.8 6.5]
(eps, iter) = ('0.02', 1) , rank(x) = [4. 1. 2. 3.] , sort(x) = [0.4 1.5 3.8 6.5]
(eps, iter) = ('0.01', 10) , rank(x) = [nan nan nan nan] , sort(x) = [nan nan nan nan]
(eps, iter) = ('0.01', 3) , rank(x) = [nan nan nan nan] , sort(x) = [nan nan nan nan]
(eps, iter) = ('0.01', 1) , rank(x) = [nan nan nan nan] , sort(x) = [nan nan nan nan]
# batch, desc order対応版
def _t(x):
return tf.transpose(x, perm=[0, 2, 1])
def _e(x):
return tf.expand_dims(x,axis=1)
def ot_sinkhorn_batch(C, a, b, eps, itr):
K = tf.exp(-C / eps)
u = tf.ones_like(a)
for _ in range(itr):
v = b / tf.linalg.matvec(_t(K),u)
u = a / tf.linalg.matvec(K,v)
P = _e(u) * (K * _e(v))
return u, v, P
def ot_sort_batch(x, eps=0.1, itr=10, desc_order=False):
l = x.shape[1]
m = x.shape[0]
i = tf.range(l, dtype=tf.float32)
y = (
tf.math.reduce_min(x, axis=1)[:, None]
+ tf.repeat(i[None, :], m, axis=0)
* tf.math.reduce_max(x, axis=1)[:, None] / l
)
if desc_order:
y = tf.reverse(y, [-1])
# stop_gradient(y)
C = (
tf.repeat(_e(y), l, axis=1)
- _t(tf.repeat(_e(x), l, axis=1))
) ** 2
a = tf.ones_like(x) / l
b = tf.ones_like(x) / l
_, _, P = ot_sinkhorn_batch(C, a, b, eps, itr)
b_hat = tf.cumsum(b, axis=1)
r = l**2 * tf.linalg.matvec(P, b_hat)
s = l * tf.linalg.matvec(_t(P), x)
return r, s
x = tf.constant([[6.5, 0.4, 1.5, 3.8,], [9,1,5,3,]])
r,s = ot_sort_batch(x)
print("x =", x)
print("rank(x) =", r)
print("sort(x) =", s)
x = tf.Tensor(
[[6.5 0.4 1.5 3.8]
[9. 1. 5. 3. ]], shape=(2, 4), dtype=float32)
rank(x) = tf.Tensor(
[[3.9084747 1.011591 2.0002174 3.035838 ]
[4. 1. 3. 2. ]], shape=(2, 4), dtype=float32)
sort(x) = tf.Tensor(
[[0.40464482 1.5001588 3.8395982 6.3556185 ]
[1. 3. 5. 9. ]], shape=(2, 4), dtype=float32)
r,s = ot_sort_batch(x, desc_order=True)
print("x =", x)
print("rank(x) =", r)
print("sort(x) =", s)
x = tf.Tensor(
[[6.5 0.4 1.5 3.8]
[9. 1. 5. 3. ]], shape=(2, 4), dtype=float32)
rank(x) = tf.Tensor(
[[0.99999994 3.9537768 3.0000052 2.022238 ]
[1. 4. 2. 3. ]], shape=(2, 4), dtype=float32)
sort(x) = tf.Tensor(
[[6.504449 3.8400276 1.4999917 0.39538595]
[9. 5. 3. 1. ]], shape=(2, 4), dtype=float32)