ホテルスポット検索¶
イメージ
yahoo(現行) |
yahoo(テスト) |
|
|
|
|
モチベーション¶
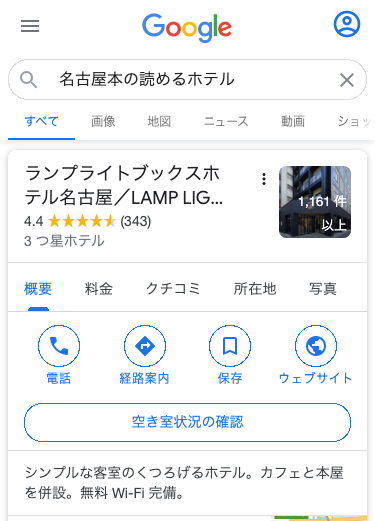
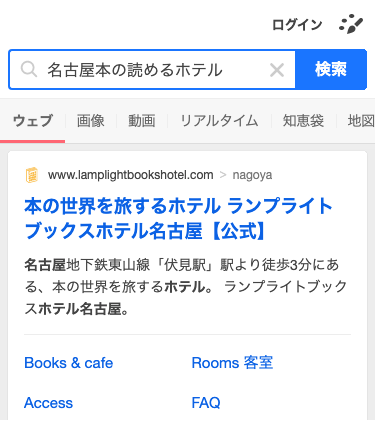
検索クエリからホテルを当てるのが難しいクエリでも、google並にDD出したい
例: クエリ = 「名古屋本の読めるホテル」
「名古屋本の読めるホテル」から「ランプライトブックスホテル名古屋」を当てるのは難しい
Q: なぜ現行で出せないのか?
→ A: 検索エンジンが当てられないから (現行では大阪ベイプラザホテルを引いてくる)
資料
【SOOM】トラベルスポット検索エンジン改善検討 https://cptl.corp.yahoo.co.jp/pages/viewpage.action?pageId=2433816897
【SOOM】トラベルスポット 検索エンジンが不正解なクエリ分析 https://cptl.corp.yahoo.co.jp/pages/viewpage.action?pageId=2545627820
【SOOM】トラベルスポット googleとの差の原因調査・伸びしろ内訳 https://cptl.corp.yahoo.co.jp/pages/viewpage.action?pageId=2527930454
問題設定¶
Input: 検索クエリと正解スポット(名前,住所)のペアが1,400万件クエリくらい
スポットの数は17,000件くらい
学習データ: 過去2年間のクエリで既存モデルが正解できるもの + 過去1ヶ月でimpsのあったクエリ
評価データ: 過去1ヶ月でimpsのあったクエリ (学習データにサブ集合になっていますが、overfitしてしまってもよいという認識でやっています)
検索の設定: 検索クエリの分散表現とスポットの分散表現の内積でランキングする
目標: すべてのクエリで正解ホテルがTOP1にランキングできること
正解データの作り方¶
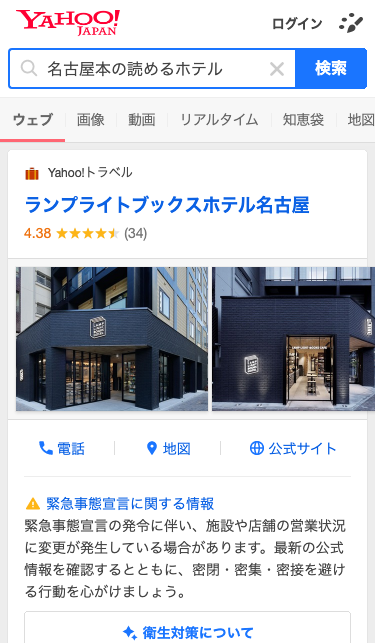
googleの検索エンジンの結果と特定のホテルページ(じゃらん、一休、楽天、Yトラベル)をユーザーがクリックしたという情報を使う
(クエリ, URL(spot id)) と (拠点名, gid (Yの拠点DBのid)) を クエリと拠点名でjoinして、spot idとgidを結びつける
spot idとgidの対応表を使って、クエリとgidを紐付ける
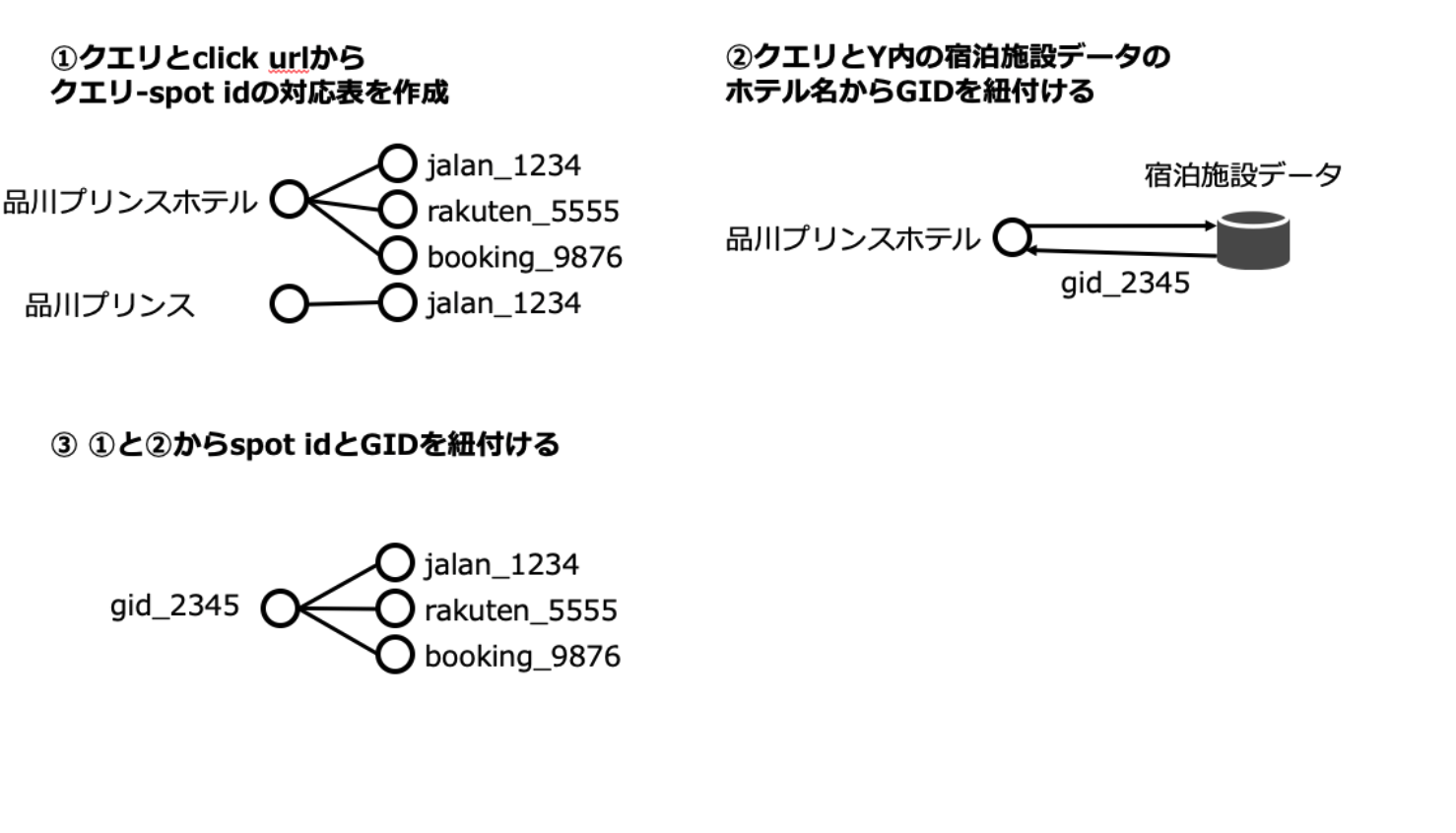
Q: クエリと正解gidが分かっているなら、クエリとgidをKVSにいれておけばいいのは?
googleへの依存度が大きいのでNGということになりました
クリックログのない超テールクエリでも、スポット検索したい
現行モデル¶
lightgbmのLabmdaRankで学習している
ラベル1: 正解ホテル
ラベル0: ランダムサンプリング30件 (1st phaseがsolrデフォルトで、2nd phaseがランダム)
特徴量
クエリと各フィールド(名前、住所、名前読み、表記ゆれリスト etc…)のスコア(tfIdf, bm25, cosine類似度…)
feature importance
tfIcf(namelist_bigram4ranking) = 1.0
bm25f(1.2__namelist_kana_webma4ranking__1__0.75) = 0.47981938893423953
tfIcf(nameyomi_trigram4ranking) = 0.11000939962088585
tfIcf(nameyomi_bigram4ranking) = 0.06630568280495444
fieldMatch(default).significance = 0.054585215879550245
bm25f(1.2__default__1__0.75) = 0.049802860960983075
fieldMatch(default).queryCompleteness = 0.04369201406793663
tfIcf(namelist_kana_webma4ranking) = 0.031924958440552986
fieldMatch(default).matches = 0.023469369066949495
tfIcf(default) = 0.023205421553969804
fieldMatch(default).weight = 0.015138581004767455
tfIdf(address4ranking) = 0.014289061473458832
fieldMatch(nameyomi_bigram4ranking).significance = 0.01370967390336565
(以下省略)
スペラーがいるので、それがクエリ訂正できるところは当てられるので表記ゆれにも対応できている
らこーはなのい → rako華乃井
らこー花野井 → rako華乃井
学習の枠組み¶
学習データは 検索クエリと正解スポット(名前, 住所)のペアで持っている
検索クエリは正規化後、Kudo EMNLP’18 SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing によって、token id化しておく
例: 「名古屋本の読めるホテル」→ [‘名古屋’, ‘本の’, ‘読’, ‘める’, ‘ホテル’] → [173, 12512, 7805, 9356, 3]
スポットの方も、名前と住所をsentencepieceによってtoken id化しておいて、住所のtoken id + 名前のtoken idとしておく
クエリとスポットのペアをM個(ミニバッチ)与えて、Metric Learning の損失関数を使って損失を計算する
損失関数内でミニバッチ内のサンプルの組み合わせを自由に決めてロスを計算する
コード例¶
constructive lossを使って、損失計算して、最適化しているコード
以下のコードは3つ (クエリ&スポット、クエリ&クエリ、スポット&スポット)のロスを計算している
@tf.function
def train_step(model_query, model_spot, optimizer,
query_ids, query_labels, spot_ids, spot_labels, margin
):
with tf.GradientTape() as tape:
query_embs = model_query(query_ids, training=True)
spot_embs = model_spot(spot_ids, training=True)
qs_loss = contrastive_loss(query_embs, query_labels, spot_embs, spot_labels, margin)
qq_loss = contrastive_loss(query_embs, query_labels, query_embs, query_labels, margin)
ss_loss = contrastive_loss(spot_embs, spot_labels, spot_embs, spot_labels, margin)
loss = qs_loss + qq_loss + ss_loss
variables = model_query.trainable_variables + model_spot.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss
constructive lossのコード
与えられたペア(inputs_col, inputs_row)のすべての組み合わせの損失を計算する
同じラベル(targets)を持つものは損失=1-内積、違うラベルを持つものは損失=max(0, 内積-マージン)
@tf.function
def contrastive_loss(
inputs_col, targets_col, inputs_row, targets_row, margin
):
sim_mat = tf.linalg.matmul(inputs_col, inputs_row, transpose_b=True)
c = tf.shape(targets_col)[0]
r = tf.shape(targets_row)[0]
targets_col_expaned = tf.transpose(tf.repeat([targets_col], repeats=r, axis=0))
targets_row_expaned = tf.repeat([targets_row], repeats=c, axis=0)
pos_mask = tf.equal(targets_col_expaned, targets_row_expaned)
neg_mask = tf.logical_and(tf.logical_not(pos_mask), tf.greater(sim_mat, margin))
return (
tf.reduce_sum(1 - tf.boolean_mask(sim_mat, pos_mask))
+ tf.reduce_sum(tf.boolean_mask(sim_mat, neg_mask))
) / tf.cast(c, tf.float32)
精度比較¶
モデル
SimpleEncoder: Embedding足し上げるだけ
Lstms: 多層LSTM (最終隠れベクトル利用)
TransfomerEncoder: Transfomerのencodeする部分 + average pooling + FFN
AttentionLstms: LSTM + Transfomer(pos-encodingなし) (最終隠れベクトル利用)
AttentionBDLstms: Bidirectional LSTM + Transfomer(pos-encodingなし) + average pooling + FFN
class SimpleEncoder(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim, mask_zero=True)
self.mean_layer = tf.keras.layers.Lambda(lambda x: tf.reduce_sum(x, axis=1))
@tf.function
def call(self, inputs, training=False):
x = self.embedding(inputs, training=training)
return tf.nn.l2_normalize(self.mean_layer(x, training=training), -1)
class Lstms(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, n_layer):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim, mask_zero=True)
self.lstm_layer = tf.keras.models.Sequential(
[tf.keras.layers.LSTM(embedding_dim, return_sequences=True) for _ in range(n_layer)]
)
@tf.function
def call(self, inputs, training=False):
x = self.embedding(inputs, training=training)
x = self.lstm_layer(x, training=training)
return tf.nn.l2_normalize(x[:, -1, :], -1)
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, d_ff, num_heads, rate=0.01):
super().__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, d_ff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
def call(self, x, training):
attn_output, _ = self.mha(x, x, x) # (batch_size, input_seq_len, d_model)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
class TransformerEncoder(tf.keras.models.Model):
def __init__(self, input_vocab_size, d_model, num_heads=8, num_layers=2,
aggregate_type="avg", maximum_position_encoding=30):
super().__init__()
self.d_model = d_model
self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, self.d_model)
self.enc_layers = tf.keras.Sequential([EncoderLayer(d_model, 2 * d_model, num_heads) for _ in range(num_layers)])
if aggregate_type == "avg":
self.aggregate = keras.layers.GlobalAveragePooling1D()
else:
self.aggregate = keras.layers.GlobalMaxPooling1D()
self.ffn = point_wise_feed_forward_network(d_model, 2 * d_model)
@tf.function
def call(self, x, training=False):
seq_len = tf.shape(x)[1]
x = self.embedding(x)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.enc_layers(x)
x = self.aggregate(x)
x = self.ffn(x)
return tf.nn.l2_normalize(x, -1)
class AttentionLstmEncoderLayer(tf.keras.Model):
def __init__(self, embedding_dim, n_heads, bidirectional_lstm=False):
super().__init__()
if not bidirectional_lstm:
self.lstm = tf.keras.layers.LSTM(embedding_dim, return_sequences=True)
else:
self.lstm = tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, return_sequences=True))
embedding_dim *= 2
self.mha = MultiHeadAttention(embedding_dim, n_heads)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.ffn = point_wise_feed_forward_network(embedding_dim, 2 * embedding_dim)
@tf.function
def call(self, inputs, training=False):
x = self.lstm(inputs, training=training)
attn_output, _ = self.mha(x, x, x)
out1 = self.layernorm1(x + attn_output)
ffn_output = self.ffn(out1)
out2 = self.layernorm2(out1 + ffn_output)
return out2
class AttentionLstms(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, n_heads, n_layer=1):
super().__init__()
self.sqrt_embedding_dim = tf.math.sqrt(tf.cast(embedding_dim, tf.float32))
self.embedding = keras.layers.Embedding(vocab_size, embedding_dim, mask_zero=True)
self.enc_layers = tf.keras.Sequential([AttentionLstmEncoderLayer(embedding_dim, n_heads) for _ in range(n_layer)])
@tf.function
def call(self, inputs, training=False):
x = self.embedding(inputs, training=training)
x *= self.sqrt_embedding_dim
x = self.enc_layers(x, training=training)
return tf.nn.l2_normalize(x[:, -1, :], -1)
class AttentionBDLstms(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, n_heads, n_layer=1, aggregate_type="avg"):
super().__init__()
self.sqrt_embedding_dim = tf.math.sqrt(tf.cast(embedding_dim, tf.float32))
self.embedding = keras.layers.Embedding(vocab_size, embedding_dim, mask_zero=True)
self.enc_layers = tf.keras.Sequential([AttentionLstmEncoderLayer(embedding_dim, n_heads, True) for _ in range(n_layer)])
if aggregate_type == "avg":
self.aggregate = keras.layers.GlobalAveragePooling1D()
else:
self.aggregate = keras.layers.GlobalMaxPooling1D()
self.ffn = point_wise_feed_forward_network(embedding_dim, 2 * embedding_dim)
@tf.function
def call(self, inputs, training=False):
x = self.embedding(inputs, training=training)
x *= self.sqrt_embedding_dim
x = self.enc_layers(x, training=training)
x = self.aggregate(x)
x = self.ffn(x)
return tf.nn.l2_normalize(x, -1)
model |
train acc. (%) |
valid acc. (%) |
valid imps weighted acc. (%) |
time |
|---|---|---|---|---|
SimpleEncoder |
89.87 |
80.51 |
80.72 |
1d0h |
Lstms(1-1) |
93.04 |
84.39 |
84.41 |
1d15h |
Lstms(2-1) |
94.31 |
86.55 |
86.53 |
1d17h |
Lstms(3-1) |
94.77 |
87.29 |
87.17 |
1d18h |
BdLstms(1-1) |
0.0 |
0.0 |
0.0 |
n.a. |
TransformerEncoder(2-2) |
96.05 |
89.4 |
89.13 |
1d19h |
TransformerEncoder(4-2) |
96.74 |
90.21 |
89.89 |
1d21h |
TransformerEncoder(6-2) |
96.35 |
89.54 |
89.29 |
2d7h |
AttentionLstms(1-1) |
94.54 |
87.15 |
87.12 |
1d20h |
AttentionLstms(2-2) |
96.07 |
89.45 |
89.26 |
2d16h |
AttentionLstms(2-1) |
96.08 |
89.42 |
89.21 |
1d21h |
AttentionLstms(3-1) |
95.74 |
88.91 |
88.75 |
1d22h |
AttentionBDLstms(1-1) |
96.81 |
90.23 |
89.93 |
2d1h |
AttentionBDLstms(2-1) |
97.82 |
92.04 |
91.75 |
2d5h |
AttentionBDLstms(3-1) |
97.46 |
91.32 |
91.11 |
2d13h |
モデルについての説明
モデル(重み含めて)は、クエリとスポットで別々 (siamese networkではない)
カッコ内の数字は(クエリ側のlayer数, スポット側のlayer数)
AttentionBDLstms系は、クエリのみそれ、スポット側はAttentionLstms
BdLstmsは双方向LSTMだが、なぜか学習に失敗した
パラメータ
embeddingの次元数=256
transformerのMultiheadAttentionのヘッド数=8, AttentionLstms系は4
minibatch size=4096
constructiveのマージン=0.7 (magin_xbm=0.8で30epoch目から0.7)
Optimizer
Adam ( \(\beta_1=0.9, \beta_2=0.99, \epsilon=1e-9\) )
最初の3500iteration(1epochくらい)まで、0から1e-3まで線形に学習率を上げていく
その後はstepごとに学習率を0.99998倍していく (最小の学習率は1e-5)
Teja ICML’20 Optimizer Benchmarking Needs to Account for Hyperparameter Tuning
5epoch目からクエリと全スポットの損失を計算している (xbm_idsが全スポットのtoken ids)
@tf.function
def train_step_xbm(model_query, model_spot, optimizer,
query_ids, query_labels, spot_ids, spot_labels,
xbm_ids, xbm_labels, margin, margin_xbm
):
with tf.GradientTape() as tape:
query_embs = model_query(query_ids, training=True)
spot_embs = model_spot(spot_ids, training=True)
xbm_embs = model_spot(xbm_ids, training=True)
qs_loss = contrastive_loss(query_embs, query_labels, spot_embs, spot_labels, margin)
qq_loss = contrastive_loss(query_embs, query_labels, query_embs, query_labels, margin)
ss_loss = contrastive_loss(spot_embs, spot_labels, spot_embs, spot_labels, margin)
qx_loss = contrastive_loss(query_embs, query_labels, xbm_embs, xbm_labels, margin_xbm)
loss = qs_loss + qq_loss + ss_loss + qx_loss
variables = model_query.trainable_variables + model_spot.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss
住所の扱い方それでいいの?¶
以下のような感じで、名前と住所を別々にencodeして、concatしてFFNに突っ込んでみた
class AttentionLstmsMultiInput(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, n_heads, n_layer=1):
super().__init__()
self.encoder1 = AttentionLstms(vocab_size, embedding_dim, n_heads, n_layer)
self.encoder2 = AttentionLstms(vocab_size, embedding_dim, n_heads, n_layer)
self.ffn = point_wise_feed_forward_network(embedding_dim, 4 * embedding_dim)
@tf.function
def call(self, inputs1, inputs2, training=False):
x1 = self.encoder1(inputs1, training=training)
x2 = self.encoder2(inputs2, training=training)
x = self.ffn(tf.concat([x1, x2], 1))
return tf.nn.l2_normalize(x, -1)
結論: 大差ないが、別々encode+concat+FFN のほうが微妙によい (パラメータ数は多いので・・・)
緑: 住所+名前でencode (今まで通り)
ピンク: 別々encode+concat+FFN
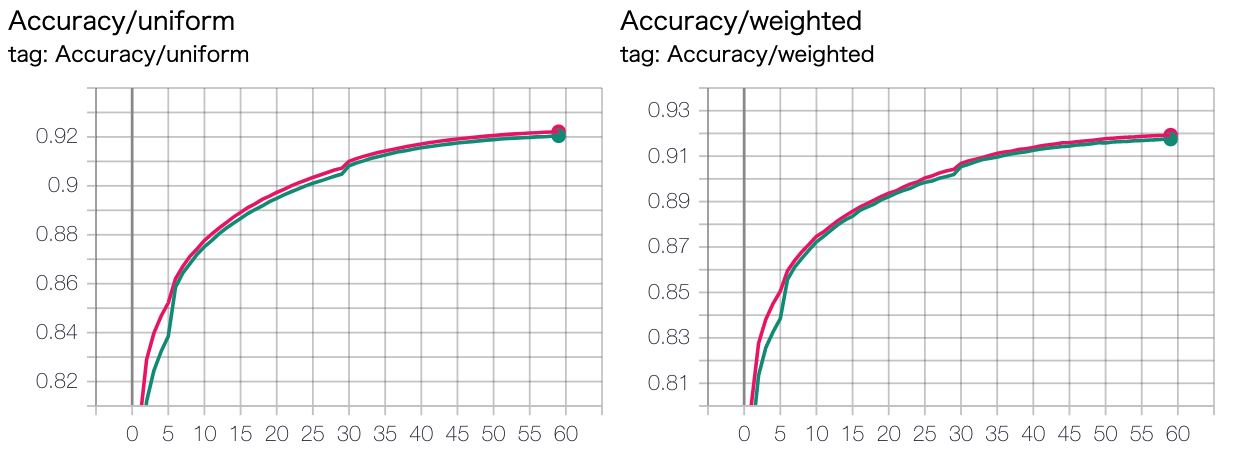
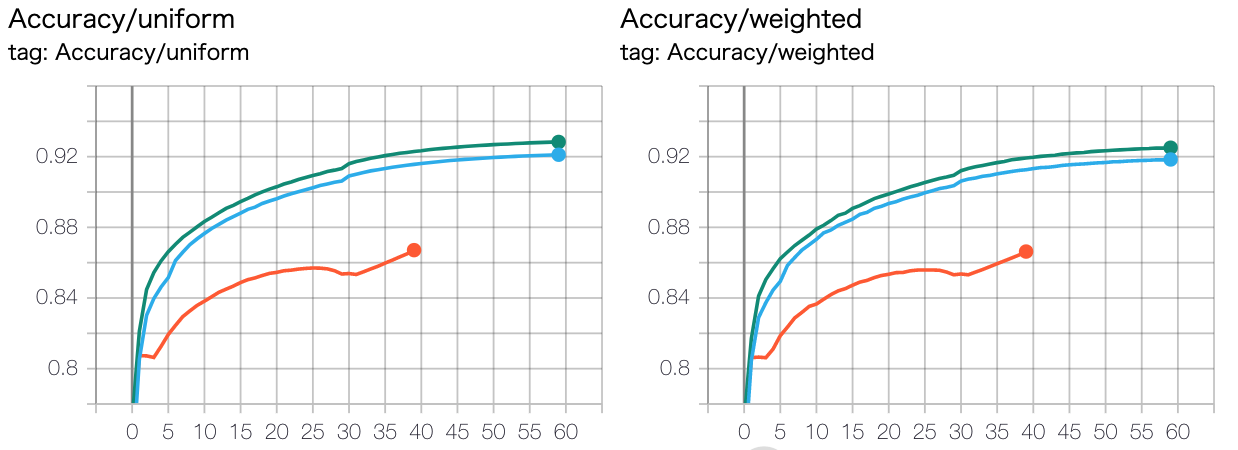
クエリとスポットでモデル別々 vs 共通¶
結論: 別々にしたほうが強い
モデル: TransfomerEncoder(2-2)
オレンジ: 別々
青: 共通
赤: スポット側の入力を住所+名前ではなく、名前のみにしたもの
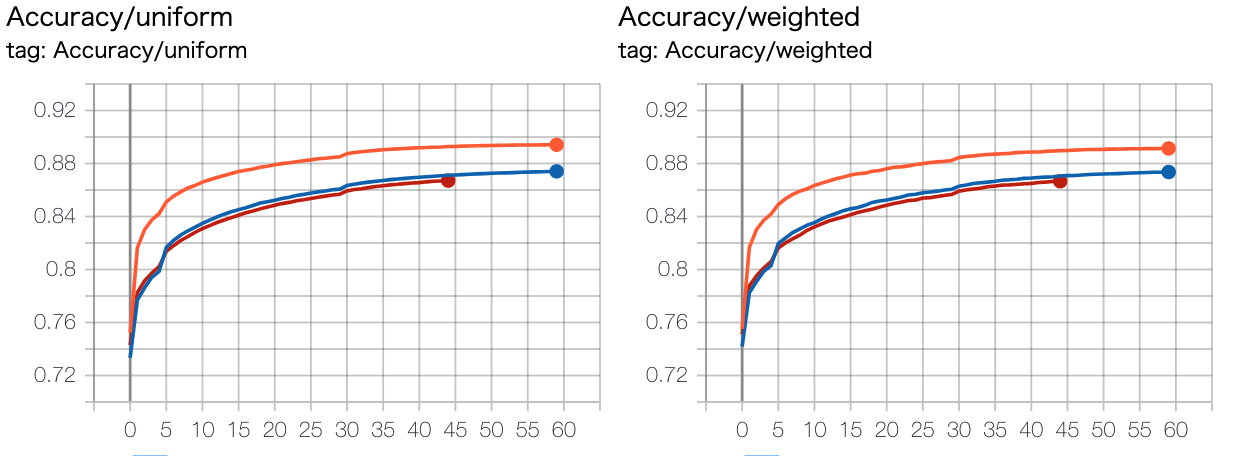
全スポット損失のマージンを最初緩めておいて、途中で厳しくする意味あるの?¶
結論: あんまり意味ないが、途中で厳しくしたほうが微妙に良い
緑: 最初margin_xbm=0.8, 30epoch目移行=0.7
ピンク: 最初から0.7
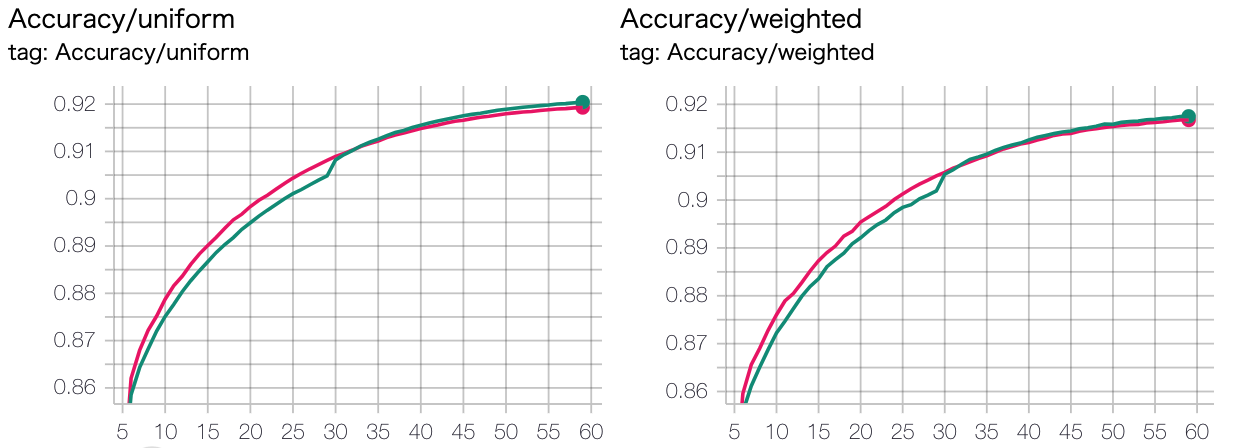
全スポット損失計算 5epoch目から(水色) vs 最初から(緑色)¶
結論: 最初からやったほうがよい
最初から全スポットとの損失を計算せずに、ちょっと経ってからやったほうがよいと思って5epoch目からやっていました
最初からやると学習失敗した記憶があったので・・・(そんなことなかったですが)
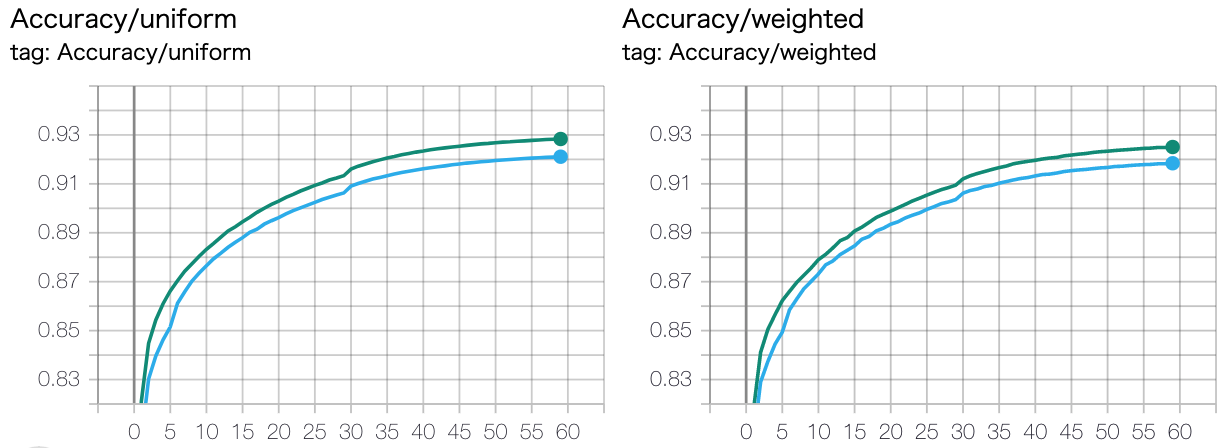
proxy系ロスに影響を受けて、全スポットのEmbeddingをProxyで代替してみた (オレンジ色)¶
モチベーション: 全スポットで損失計算して、backpropするのが重たい (ホテル数がすくないので何とかなっているが…)
結論: ダメだった
proxyは学習可能な変数で、毎epochごとに model_spotを使って計算しなおす設定 (2epoch目からスタート)
感想: 学習不可能な設定にしたほうがよかったかもしれない (proxyの方を動かして損失下がっても嬉しくない)
class Proxy(tf.keras.Model):
def __init__(self, num, embedding_dim):
super().__init__()
self.embedding = tf.keras.layers.Embedding(num, embedding_dim, mask_zero=False)
@tf.function
def call(self, inputs, training=False):
x = self.embedding(inputs, training=training)
return x
def set_embedding_weights(self, weights):
self.embedding.set_weights([weights])
@tf.function
def train_step_proxy(model_query, model_spot, optimizer,
query_ids, query_labels, spot_ids, spot_labels,
model_proxy, proxy_labels, margin, margin_xbm
):
with tf.GradientTape() as tape:
query_embs = model_query(query_ids, training=True)
spot_embs = model_spot(spot_ids, training=True)
proxy_embs = model_proxy(proxy_labels, training=True)
qs_loss = contrastive_loss(query_embs, query_labels, spot_embs, spot_labels, margin)
qq_loss = contrastive_loss(query_embs, query_labels, query_embs, query_labels, margin)
ss_loss = contrastive_loss(spot_embs, spot_labels, spot_embs, spot_labels, margin)
qp_loss = contrastive_loss(query_embs, query_labels, proxy_embs, proxy_labels, margin_xbm)
sp_loss = contrastive_loss(spot_embs, spot_labels, proxy_embs, proxy_labels, margin)
loss = qs_loss + qq_loss + ss_loss + qp_loss + sp_loss
variables = model_query.trainable_variables + model_spot.trainable_variables + model_proxy.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss
学習率スケジューリング¶
一番上の緑: 7000step (約2epoch) までの間0から1e-3まで線形にあげていって、 その後はstepごとに学習率を0.99998倍していく (最小の学習率は1e-5)
水色: 1e-3からはじめてstepごとに学習率を0.99998倍していく (最小の学習率は1e-5) (warmupなし)
一番下の緑: 学習率 1e-4で固定
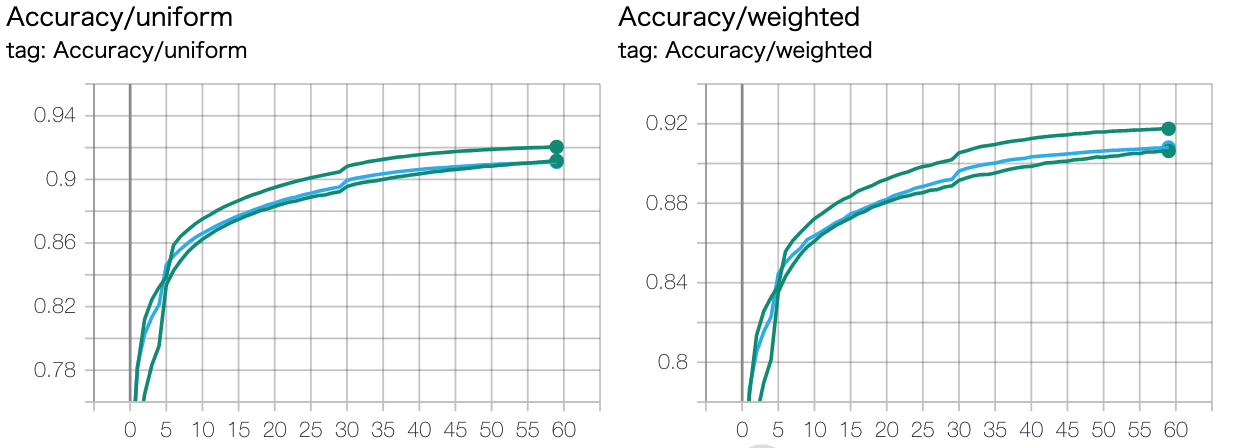
感想
warmupはしたほうがよいのでは
1e-4固定は、後半まだ微妙に伸びそうではあるので、最小1e-5は小さすぎたかもしれない
アプライ¶
参考文献¶
Metric Learning のpapers
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin. Attention Is All You Need. In NIPS 2017.